Next: 8.10 GridSolvers Up: 8. Grid Unit Previous: 8.8 GridMain Usage Contents Index
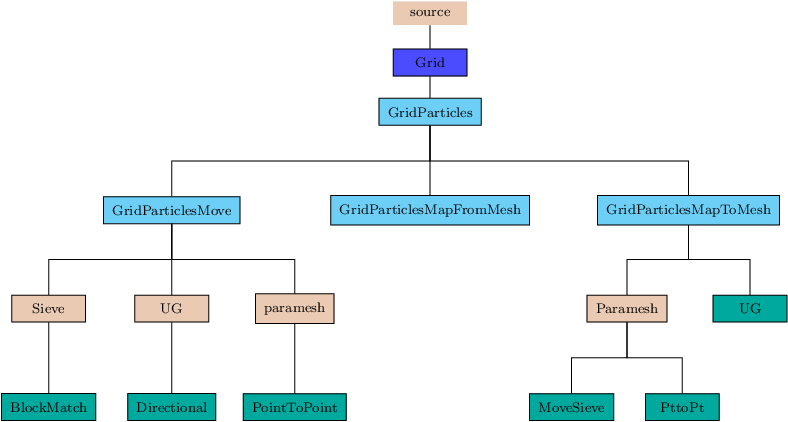
FLASH is primarily an Eulerian code, however, there is support for tracing the flow using Lagrangian particles. In FLASH4 we have generalized the interfaces in the Lagrangian framework of the Grid unit in such a way that it can also be used for miscellaneous non-Eulerian data such as tracing the path of a ray through the domain, or tracking the motion of solid bodies immersed in the fluid. FLASH also uses active particles with mass in cosmological simulations, and charged particles in a hybrid PIC solver. Each particle has an associated data structure, which contains fields such as its physical position and velocity, and relevant physical attributes such as mass or field values in active particles. Depending upon the time advance method, there may be other fields to store intermediate values. Also, depending upon the requirements of the simulation, other physical variables such as temperature etc. may be added to the data structure. The GridParticles subunit of the Grid unit has two sub-subunits of its own. The GridParticlesMove sub-subunit moves the data structures associated with individual particles when the particles move between blocks; the actual movement of the particles through time advancement is the responsibility of the Particles unit. Particles move from one block to another when their time advance places them outside their current block. In AMR, the particles can also change their block through the process of refinement and derefinement. The GridParticlesMap sub-subunit provides mapping between particles data and the mesh variables. The mesh variables are either cell-centered or face-centered, whereas a particle's position could be anywhere in the cell. The GridParticlesMap sub-subunit calculates the particle's properties at its position from the corresponding mesh variable values in the appropriate cell . When using active particles, this sub-subunit also maps the mass of the particles onto the specified mesh variable in appropriate cells. The next sections describe the algorithms for moving and mapping particles data.
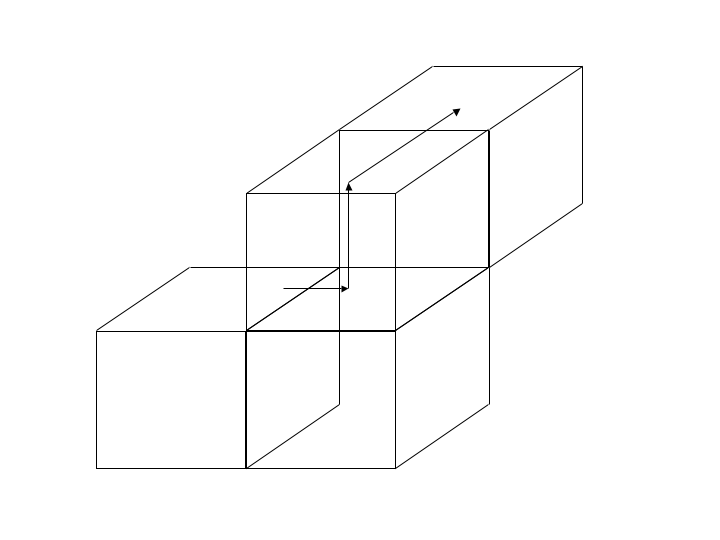
At the end of these steps, all particles will have reached their destination blocks, including those that move to a neighbor on the corner. Figure 8.9 illustrates the steps in getting a particle to its correct destination.
As a part of the data cached by Paramesh, there is wealth of information about the neighborhood of all the blocks on a processor. This information includes the processor and block number of all neighbors (face and corners) if they are at the same refinement level. If those neighbors are at lower refinement level, then the neighbor block is in reality the current block's parent's neighbor, and the parent's neighborhood information is part of the cached data. Similarly, if the neighbor is at a higher resolution then the current blocks neighbor is in reality the parent of the neighbor. The parent's metadata is also cached, from which information about all of its children can be derived. Thus it is possible to determine the processor and block number of the destination block for each particle. The PointToPoint implementation finds out the destinations for every particles that is getting displaced from its block. Particles going to local destination blocks are moved first. The remaining particles are sorted based on their destination processor number, followed by a couple of global operations that allow every processor to determine the number of particles it is expected to receive from all of the other processors. A processor then posts asynchronous receives for every source processor that had at least one particle to send to it. In the next step, the processor cycles through the sorted list of particles and sends them to the appropriate destinations using synchronous mode of communition.
In general the mapping is performed using the grid routines in the GridParticlesMapToMesh directory and the particle routines in the ParticlesMapping directory. Here, the particle subroutines map the particles' attribute into a temporary array which is independent of the current state of the grid, and the grid subroutines accumulate the mapping from the array into valid cells of the computational domain. This means the grid subroutines accumulate the data according to the grid block layout, the block refinement details, and the simulation boundary conditions. As these details are closely tied with the underlying grid, there are separate implementations of the grid mapping routines for UG and PARAMESH simulations.
The implementations are required to communicate information in a relatively non-standard way. Generally, domain decomposition parallel programs do not write to the guard cells of a block, and only use the guard cells to represent a sufficient section of the domain for the current calculation. To repeat the calculation for the next time step, the values in the guard cells are refreshed by taking updated values from the internal section of the relevant block. In FLASH4, PARAMESH refreshes the values in the guard cells automatically, and when instructed by a Grid_fillGuardCells call.
In contrast, the guard cell values are mutable in the particle mapping problem. Here, it is possible that a portion of the particle's attribute is accumulated in a guard cell which represents an internal cell of another block. This means the value in the updated guard cell must be communicated to the appropriate block. Unfortunately, the mechanism to communicate information in this direction is not provided by PARAMESH or UG grid. As such, the relevant communication is performed within the grid mapping subroutines directly.
In both PARAMESH and UG implementations, the particles' attribute is “smeared” across a temporary array by the generic particle mapping subroutine. Here, the temporary array represents a single leaf block from the local processor. In simulations using the PARAMESH grid, the temporary array represents each LEAF block from the local processor in turn. We assign a particle's attribute to the temporary array when that particle exists in the same space as the current leaf block. For details about the attribute assignment schemes available to the particle mapping sub-unit, please refer to Sec:Particles Mapping.
After particle assignment, the Grid sub-unit applies simulation boundary conditions to those temporary arrays that represent blocks next to external boundaries. This may change the quantity and location of particle assignment in the elements of the temporary array. The final step in the process involves accumulating values from the temporary array into the correct cells of the computational domain. As mentioned previously, there are different strategies for UG and PARAMESH grids, which are described in Sec:UniformGridParticleMap and Sec:ParameshGridParticleMap, respectively.
-defines=DEBUG_GRIDMAPPARTICLES
The Uniform Grid algorithm for accumulating particles' attribute on the grid is similar to the particle redistribution algorithm described in Sec: ug_algorithm. We once again apply the concept of directional movement to minimize the number of communication steps:
When the guard cell's value is packed into the send buffer, a single value is also packed which is a 1-dimensional representation of the destination cell's N-dimensional position. The value is obtained by using an array equation similar to that used by a compiler when mapping an array into contiguous memory. The receiving processor applies a reverse array equation to translate the value into N-dimensional space. The use of this communication protocol is designed to minimize the message size.
At the end of communication, each local temporary buffer contains accumulated values from guard cells of another block. The temporary buffer is then copied into the solution array.
There are two implementations of the AMR algorithms for accumulating particles' attribute on the grid. They are inspired by a particle redistribution algorithms Sieve and Point to Point described in Sec: sieve_algorithm and Sec: ptop_algorithm respectively.
The MoveSieve implementation of the mapping algorithm uses the
same back and forth communication pattern as Sieve to minimize
the number of message exchanges. That is, processor ![]() sends to
sends to
![]() and receives from
and receives from
![]() , where,
, where, ![]() is the local processor number and
is the local processor number and ![]() is the count of the buffer
exchange round. As such, this communication pattern involves a
processor exchanging data with its nearest neighbor processors first.
This is appropriate here because the block distribution generated by
the space filling curve should be high in data locality, i.e.,
nearest neighbor blocks should be placed on the same processor or
nearest neighbor processors.
is the count of the buffer
exchange round. As such, this communication pattern involves a
processor exchanging data with its nearest neighbor processors first.
This is appropriate here because the block distribution generated by
the space filling curve should be high in data locality, i.e.,
nearest neighbor blocks should be placed on the same processor or
nearest neighbor processors.
Similarly, the Point to Point implementation of the mapping algorithm exploits the cached neighborhood knowledge, and uses a judicious combination of global communications with asynchronous receives and synchronous sends, as described in Sec: ptop_algorithm. Other than their communication patterns, the two implementations are very similar as described below.
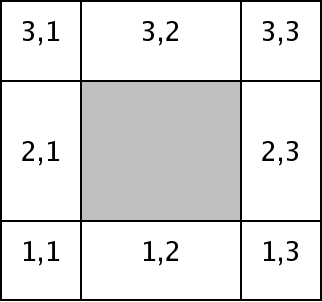
The guard cell region decomposition described in Step 2 is illustrated in Figure 8.10. Here, the clear regions correspond to guard cells and the gray region corresponds to internal cells. Each guard cell region contains cells which correspond to the internal cells of a single neighboring block at the same refinement.
We use this decomposition as it makes it possible to query public PARAMESH data structures which contain the block and process identifier of the neighboring block at the same refinement. However, at times this is not enough information for finding the block neighbor(s) in a refined grid. We therefore categorize neighboring blocks as: Existing on the same processor, existing on another processor and the block and process ID are known, and existing on another processor and the block and process ID are unknown. If the block and process identifier are unknown we use the FLASH4 corner ID. This is a viable alternative as the corner ID of a neighboring block can always be determined.
The search process also identifies the refinement level of the neighboring block(s). This is important as the guard cell values cannot be directly accumulated into the internal cells of another block if the blocks are at a different refinement levels. Instead the values must be operated on in processes known as restriction and prolongation (see Sec:gridinterp). We perform these operations directly in the GridParticlesMapToMesh routines, and use quadratic interpolation during prolongation.
Guard cell data is accumulated in blocks existing on the same processor, or packed into a send buffer ready for communication. When packed into the send buffer, we keep values belonging to the same guard cell region together. This enables us to describe a whole region of guard cell data by a small amount of metadata. The metadata consists of: Destination block ID, destination processor ID, block refinement level difference, destination block corner ID (IAXIS, JAXIS, KAXIS) and start and end coordinates of destination cells (IAXIS, JAXIS, KAXIS). This is a valid technique because there are no gaps in the guard cell region, and is sufficient information for a receiving processor to unpack the guard cell data correctly.
We size the send / receive buffers according to the amount of data that needs to be communicated between processors. This is dependent upon how the PARAMESH library distributes blocks to processors. Therefore, in order to size the communication buffers economically, we calculate the number of guard cells that will accumulate on blocks belonging to another processor. This involves iterating over every single guard cell region, and keeping a running total of the number of off-processor guard cells. This total is added to the metadata total to give the size of the send buffer required on each processor. We use the maximum of the send buffer size across all processors as the local size for the send / receive buffer. Choosing the maximum possible size prevents possible buffer overflow when an intermediate processor passes data onto another processor.
After the point to point communication in step 6, the receiving processor scans the destination processor identifier contained in each metadata block. If the data belongs to this processor it is unpacked and accumulated into the central cells of the relevant leaf block. As mentioned earlier, it is possible that some guard cell sections do not have the block and processor identifier. When this happens, the receiving processor attempts to find the same corner ID in one of its blocks by performing a linear search over each of its leaf blocks. Should there be a match, the guard cells are copied into the matched block. If there is no match, the guard cells are copied from the receive buffer into the send buffer, along with any guard cell region explicitly designated for another processor. The packing and unpacking will continue until all send buffers are empty, as indicated by the result of the collective communication.
It may seem that the algorithm is unnecessarily complicated, however, it is the only viable algorithm when the block and process identifiers of the nearest block neighbors are unknown. This is the situation in FLASH3.0, in which some data describing block and process identifiers are yet to be extracted from PARAMESH. As an aside, this is different to the strategy used in FLASH2, in which the entire PARAMESH tree structure was copied onto each processor. Keeping a local copy of the entire PARAMESH tree structure on each processor is an unscalable approach because increase in the levels of resolution increases the meta-data memory overhead, which restricts the size of active particle simulations. Therefore, Point to Point method is a better option for larger simulations, and significantly, simulations that run on massively parallel processing (MPP) hardware architectures.
In FLASH3.1 we added a routine which searches non-public PARAMESH data to obtain all neighboring block and process identifiers. This discovery greatly improves the particle mapping performance because we no longer need to perform local searches on each processor for blocks matching a particular corner ID.
As another consequence of this discovery, we are able to experiment with alternative mapping algorithms that require all block and process IDs. From FLASH3.1 on we also provide a non-blocking point to point implementation in which off-processor cells are sent directly to the appropriate processor. Here, processors receive messages at incremented positions along a data buffer. These messages can be received in any order, and their position in the data buffer can change from run to run. This is very significant because the mass accumulation on a particular cell can occur in any order, and therefore can result in machine precision discrepancies. Please be aware that this can actually lead to slight variations in end-results between two runs of the exact same simulation.