Next: 8.7 Chombo Up: 8. Grid Unit Previous: 8.5 Uniform Grid Contents Index
The default package in FLASH is PARAMESH (MacNeice et al. 1999) for implementing the adaptive mesh
refinement (AMR) grid. PARAMESH uses a block-structured adaptive mesh
refinement scheme similar to others in the literature (e.g., Parashar
1999; Berger & Oliger 1984; Berger & Colella 1989; DeZeeuw & Powell
1993). It also shares ideas with schemes which refine on an
individual cell basis (Khokhlov 1997). In block-structured AMR, the
fundamental data structure is a block of cells arranged in a logically
Cartesian fashion. “Logically Cartesian” implies that each
cell can be specified using a block identifier
(processor number and local block number) and a coordinate triple
![]() , where
, where
![]() ,
,
![]() , and
, and
![]() refer to the
refer to the ![]() -,
-, ![]() -, and
-, and ![]() -directions,
respectively. It does not require a physically rectangular coordinate system;
for example a spherical grid can be indexed in this same manner.
-directions,
respectively. It does not require a physically rectangular coordinate system;
for example a spherical grid can be indexed in this same manner.
The complete computational grid consists of a collection
of blocks with different physical cell sizes, which are related to
each other in a hierarchical fashion using a tree data structure. The
blocks at the root of the tree have the largest cells, while their
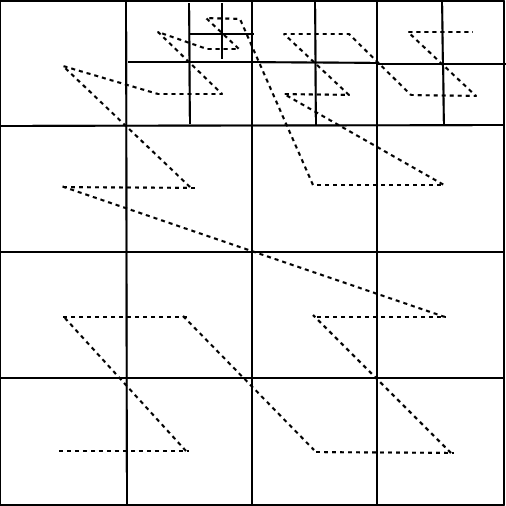
children have smaller cells and are said to be refined. Three rules
govern the establishment of refined child blocks in PARAMESH. First, a
refined child block must be one-half as large as its parent block in
each spatial dimension. Second, a block's children must be nested;
i.e., the child blocks must fit within their parent block and cannot
overlap one another, and the complete set of children of a block must
fill its volume. Thus, in ![]() dimensions a given block has either zero
or
dimensions a given block has either zero
or ![]() children. Third, blocks which share a common border may not
differ from each other by more than one level of refinement.
children. Third, blocks which share a common border may not
differ from each other by more than one level of refinement.
A simple two-dimensional domain is shown in
Figure 8.5, illustrating the rules above. Each
block contains
![]() interior
cells and a set of guard cells. The guard cells contain boundary
information needed to update the interior cells. These can be obtained
from physically neighboring blocks, externally specified boundary
conditions, or both.
interior
cells and a set of guard cells. The guard cells contain boundary
information needed to update the interior cells. These can be obtained
from physically neighboring blocks, externally specified boundary
conditions, or both.
|
PARAMESH handles the filling of guard cells with information from other blocks or, at the boundaries of the physical domain, from an external boundary routine (see Sec:BndryCond). If a block's neighbor exists and has the same level of refinement, PARAMESH fills the corresponding guard cells using a direct copy from the neighbor's interior cells. If the neighbor has a different level of refinement, the data from the neighbor's cells must be adjusted by either interpolation (to a finer level of resolution) or averaging (to a coarser level)--see Sec:gridinterp below for more information. If the block and its neighbor are stored in the memory of different processors, PARAMESH handles the appropriate parallel communications (blocks are never split between processors). The filling of guard cells is a global operation that is triggered by calling Grid_fillGuardCells.
Grid Interpolation is also used when filling the blocks of children newly created in the course of automatic refinement. This happens during Grid_updateRefinement processing. Averaging is also used to regularly update the solution data in at least one level of parent blocks in the oct-tree. This ensures that after leaf nodes are removed during automatic refinement processing (in regions of the domain where the mesh is becoming coarser), the new leaf nodes automatically have valid data. This averaging happens as an initial step in Grid_fillGuardCells processing.
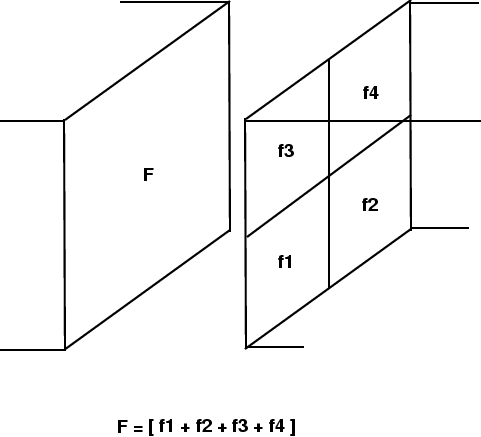
PARAMESH also enforces flux conservation at jumps in refinement, as described by Berger and Colella (1989). At jumps in refinement, the fluxes of mass, momentum, energy (total and internal), and species density in the fine cells across boundary cell faces are summed and passed to their parent. The parent's neighboring cell will be at the same level of refinement as the summed flux cell because PARAMESH limits the jumps in refinement to one level between blocks. The flux in the parent that was computed by the more accurate fine cells is taken as the correct flux through the interface and is passed to the corresponding coarse face on the neighboring block (see Figure 8.6). The summing allows a geometrical weighting to be implemented for non-Cartesian geometries, which ensures that the proper volume-corrected flux is computed.
|
FLASH has its own oneBlock data structure that stores block specific information. This data structure keeps the physical coordinates of each cell in the block. For each dimension, the coordinates are stored for the LEFT_EDGE, the RIGHT_EDGE and the center of the cell. The coordinates are determined from “cornerID” which is also a part of this data structure.
The concept of cornerID was introduced in FLASH3; it serves three
purposes. First, it creates a unique global identity for every cell
that can come into existence at any time in the course of the
simulation. Second, it can prevent machine precision error from
creeping into the spatial coordinates calculation. Finally, it can
help pinpoint the location of a block within the oct-tree of
PARAMESH. Another useful integer variable is the concept of a stride. A stride indicates the spacing factor between one cell and
the cell directly to its right when calculating the cornerID. At the
maximum refinement level, the stride is ![]() , at the next higher level
it is
, at the next higher level
it is ![]() , and so on. Two consecutive cells at refinement level
, and so on. Two consecutive cells at refinement level ![]() are numbered with a stride of
are numbered with a stride of
![]() where
where
![]() .
.
The routine Grid_getBlkCornerID provides a convenient way for the user to retrieve the location of a block or cell. A usage example is provided in the documentation for that routine. The user should retrieve accurate physical and grid coordinates by calling the routines Grid_getBlkCornerID, Grid_getCellCoords, Grid_getBlkCenterCoords and Grid_getBlkPhysicalSize, instead of calculating their own from local block information, since they take advantage of the cornerID scheme, and therefore avoid the possibility of introducing machine precision induced numerical drift in the calculations.
In the AMR context, the term prolongation is used to refer to data interpolation (because it is used when the tree of blocks grows longer). Similarly, the term restriction is used to refer to fine-to-coarse data averaging.
The algorithm used for restriction is straightforward (equal-weight) averaging in Cartesian coordinates, but has to take cell volume factors into account for curvilinear coordinates; see Sec:Non-Cart Prol/Rest.
PARAMESH supports various interpolation schemes, to which user-specified interpolation schemes can be added. FLASH4 currently allows to choose between two interpolation schemes:
The versions of PARAMESH supplied with FLASH4 supply their own default interpolation scheme, which is used when FLASH4 is configured with the -gridinterpolation=native setup option (see Sec:ListSetupArgs). The default schemes are only appropriate for Cartesian coordinates. If FLASH4 is configured with curvilinear support, an alternative scheme (appropriate for all supported geometries) is compiled in. This so-called “monotonic” interpolation attempts to ensure that interpolation does not introduce small-scale non-monotonicity in the data. The order of “monotonic” interpolation can be chosen with the interpol_order runtime parameter. See Sec:Non-Cart Prol/Rest for some more details on prolongation for curvilinear coordinates. At setup time, monotonic interpolation is the default interpolation used.
FLASH4 provides three ways to deal with this:
VARIABLE dens TYPE: PER_VOLUME
This behavior is available in both PARAMESH 2 and PARAMESH 4.
It is enabled by setting the
convertToConsvdForMeshCalls
runtime parameter and corresponds roughly to FLASH2 with
conserved_var enabled.
This behavior is available only for PARAMESH 4.
As of FLASH4, this is the default behavior whenever available.
It can be enabled explicitly
(only necessary in setups that change the default) by setting the
convertToConsvdInMeshInterp runtime parameter.
Löhner's estimator is a modified second derivative, normalized by the average of the gradient over one computational cell. In one dimension on a uniform mesh, it is given by
![$\displaystyle E_{i} = { \frac{ \mid u_{i+1} - 2u_{i} + u_{i-1} \mid} { \mid u_{...
...+ \epsilon [ \mid u_{i+1} \mid + 2 \mid u_{i} \mid + \mid u_{i-1} \mid ] } } ,$](img194.png) |
(8.1) |
When extending this criterion to multidimensions, all cross derivatives are computed, and the following generalization of the above expression is used
![$\displaystyle E_{i_1i_2i_3} = \left\{ {\displaystyle \sum_{pq}\left({ \frac{\pa...
...over \partial x_p\partial x_q} \Delta x_p\Delta x_q \right]^2 } \right\}^{1/2},$](img197.png) |
(8.2) |
The estimator actually used in FLASH4's default refinement criterion is a modification of the above, as follows:
![$\displaystyle E_{i} = { \mid u_{i+2} - 2u_{i} + u_{i-2} \mid \over \mid u_{i+2}...
...d + \epsilon [ \mid u_{i+2} \mid + 2 \mid u_{i} \mid + \mid u_{i-2} \mid ] } ,$](img199.png) |
(8.3) |
When extending this criterion to multidimensions, all cross derivatives are computed, and the following generalization of the above expression is used
![$\displaystyle E_{i_Xi_Yi_Z} = \left\{ {\displaystyle \sum_{pq}\left({\partial^2...
...\vert u_{pq}\right\vert}\over \Delta x_p\Delta x_q} \right]^2 } \right\}^{1/2},$](img200.png) |
(8.4) |
The constant
![]() is by default given a value of
is by default given a value of ![]() , and can be overridden
through the refine_filter_# runtime parameters.
Blocks are marked for refinement when the value of
, and can be overridden
through the refine_filter_# runtime parameters.
Blocks are marked for refinement when the value of
![]() for any of the
block's cells exceeds a threshold given by the runtime parameters
refine_cutoff_#, where the number #
matching the number of the refine_var_# runtime parameter
selecting the refinement variable.
Similarly, blocks are marked for derefinement when the values of
for any of the
block's cells exceeds a threshold given by the runtime parameters
refine_cutoff_#, where the number #
matching the number of the refine_var_# runtime parameter
selecting the refinement variable.
Similarly, blocks are marked for derefinement when the values of
![]() for all
of the
block's cells lie below another threshold given by the runtime parameters
derefine_cutoff_#.
for all
of the
block's cells lie below another threshold given by the runtime parameters
derefine_cutoff_#.
Although PPM
is formally second-order and its leading error terms scale as the
third derivative, we have found the second derivative criterion to
be very good at detecting discontinuities and sharp features in the
flow variable ![]() . When Particles (active or tracer) are being
used in a simulation, their count in a block can also be used as a
refinement criterion by setting refine_on_particle_count to true
and setting max_particles_per_blk to the desired count.
. When Particles (active or tracer) are being
used in a simulation, their count in a block can also be used as a
refinement criterion by setting refine_on_particle_count to true
and setting max_particles_per_blk to the desired count.
During the distribution step, each block is assigned a weight which estimates the relative amount of time required to update the block. The Morton number of the block is then computed by interleaving the bits of its integer coordinates, as described by Warren and Salmon (1987). This reordering determines its location along the space-filling curve. Finally, the list of all blocks is partitioned among the processors using the block weights, equalizing the estimated workload of each processor. By default, all leaf-blocks are weighted twice as heavily as all other blocks in the simulation.
FLASH3.2 added additional support in the standard implementation
of refinement routine
Grid_markRefineDerefine
for enforcing a maximum on refinement based
on location or simulation time. These work by effectively lowering the
absolute ceiling on refinement level represented by lrefine_max.
See the following runtime parameters: